Uranus /work/kai> lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 24
On-line CPU(s) list: 0-23
Vendor ID: GenuineIntel
Model name: 12th Gen Intel(R) Core(TM) i9-12900K
CPU family: 6
Model: 151
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 1
Stepping: 2
CPU max MHz: 6700.0000
CPU min MHz: 800.0000
BogoMIPS: 6374.40
Flags: 略
Virtualization features:
Virtualization: VT-x
Caches (sum of all):
L1d: 640 KiB (16 instances)
L1i: 768 KiB (16 instances)
L2: 14 MiB (10 instances)
L3: 30 MiB (1 instance)
NUMA:
NUMA node(s): 1
NUMA node0 CPU(s): 0-23
Vulnerabilities:
Itlb multihit: Not affected
L1tf: Not affected
Mds: Not affected
Meltdown: Not affected
Mmio stale data: Not affected
Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling
Srbds: Not affected
Tsx async abort: Not affected
Uranus /work/kai> lsmem
RANGE SIZE STATE REMOVABLE BLOCK
0x0000000000000000-0x000000007fffffff 2G online yes 0
0x0000000100000000-0x000000207fffffff 126G online yes 2-64
Memory block size: 2G
Total online memory: 128G
Total offline memory: 0B
Create input files with only one variable. For instance, change CPU into 2, 4, 6, ..., 22, 24 with mem=40GB ,same molecular structure and same method/basis set.
%nprocshared=2
%mem=40GB
%chk=test_cpu2.chk
# mp2/aug-cc-pVDZ opt freq
Then grep 'Elapsed time:' from all output files.
Uranus /work/kai> grep 'Elapsed time:' *.log
test_cpu10.log: Elapsed time: 0 days 0 hours 2 minutes 38.7 seconds.
test_cpu12.log: Elapsed time: 0 days 0 hours 2 minutes 35.1 seconds.
test_cpu14.log: Elapsed time: 0 days 0 hours 2 minutes 30.8 seconds.
test_cpu16.log: Elapsed time: 0 days 0 hours 2 minutes 28.8 seconds.
test_cpu18.log: Elapsed time: 0 days 0 hours 2 minutes 33.4 seconds.
test_cpu20.log: Elapsed time: 0 days 0 hours 2 minutes 35.2 seconds.
test_cpu22.log: Elapsed time: 0 days 0 hours 2 minutes 31.8 seconds.
test_cpu24.log: Elapsed time: 0 days 0 hours 2 minutes 34.8 seconds.
test_cpu2.log: Elapsed time: 0 days 0 hours 7 minutes 17.2 seconds.
test_cpu4.log: Elapsed time: 0 days 0 hours 4 minutes 14.5 seconds.
test_cpu6.log: Elapsed time: 0 days 0 hours 3 minutes 11.6 seconds.
test_cpu8.log: Elapsed time: 0 days 0 hours 2 minutes 42.3 seconds.
使用 g16 軟體,以及 MP2/aug-cc-pVDZ 理論方法,進行苯環結構優化與頻率計算,在 mem 都是 40GB 的況下 (另外測試過 mem 在 20GB 以上,速度基本上僅差0.1秒左右,更高階理論方法還需要測試)。
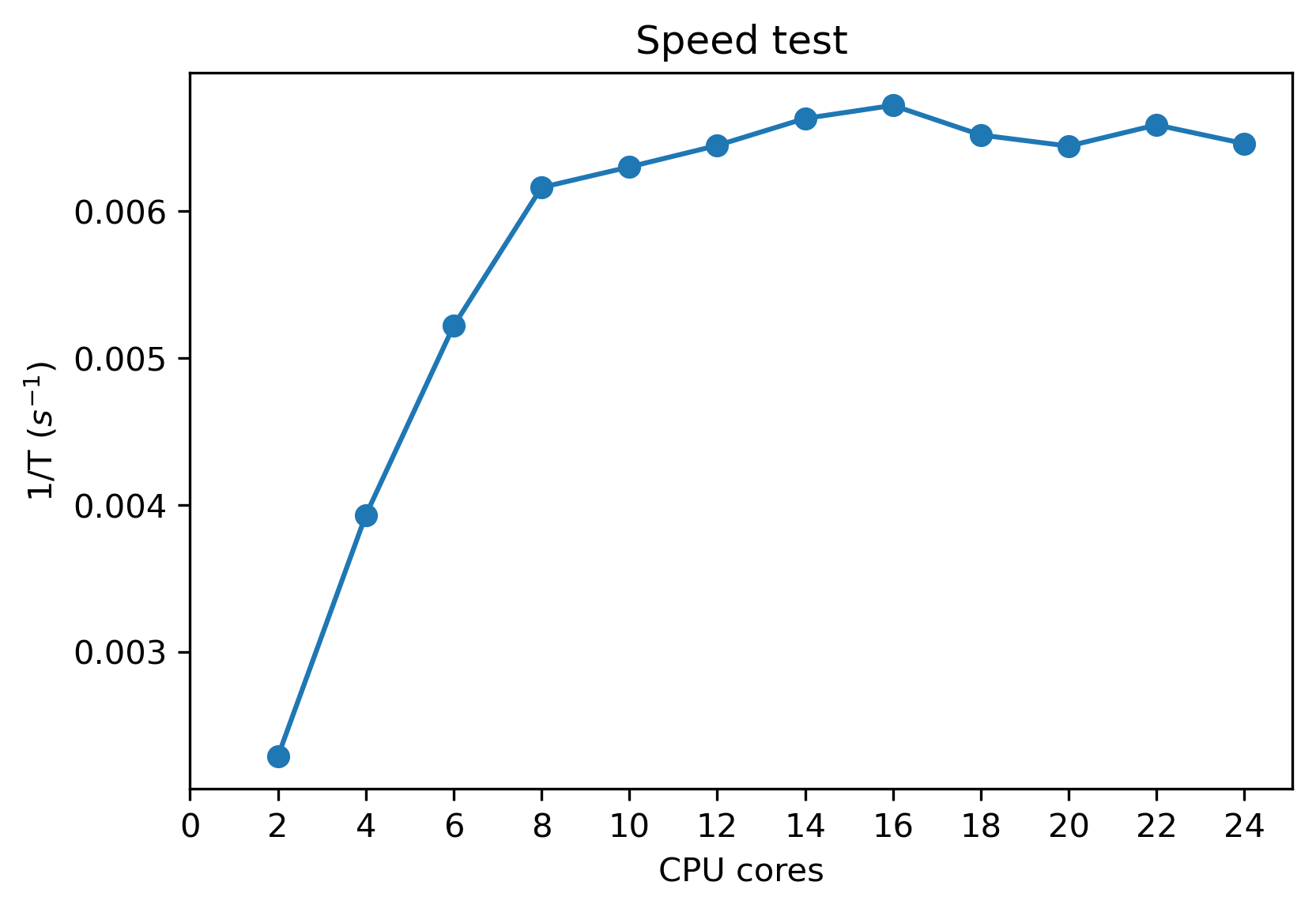
結論:八核心之後速度沒有明顯的提升,緩慢提升到 16 核後沒有規律(可能是用到剩餘的8個執行緒)
總共 8 個相同的input files,為避免執行緒的干擾,設定為16核心平分:
1. 同時計算八個(nprocshared=2/mem=16): 6004.9 sec
2. 兩倍[同時計算四個(nprocshared=4/mem=32)]:3238.6 sec
3. 四倍[同時計算兩個(nprocshared=8/mem=64)]:1816.4 sec
4. 八倍[計算一個(nprocshared=16/mem=128)]:1202.4 sec
結論:在資源平均分配的情況下,一次計算一個會是最有效率的方法。
使用140.123.79.54, 140.123.79.47, 140.123.79.97,計算相同的input file
%nprocshared=2
%mem=16GB
# mp2/aug-cc-pVDZ opt=(calcfc,cartesian,maxcyc=50) freq
#苯環結構省略
結果:
(54) 12th Gen Intel(R) Core(TM) i9-12900K: 7 minutes 19.5 seconds
(47) 11th Gen Intel(R) Core(TM) i9-11900KF: 8 minutes 24.2 seconds
(97) Intel(R) Core(TM) i7 CPU 930: 37 minutes 0.1 seconds